公众号:PowerBI生命管理大师学谦,同步更新,敬请关注
第4章 上下文和筛选
编写 DAX 公式时要掌握的核心概念是上下文。
DAX 作为一门动态数据分析语言,与 Excel 函数、SQL 查询 和 Power Query 脚本有着根本不同的原因就在于上下文的概念。以上所述的所有其他语言的公式只会在数据发生变化时才会返回不同的结果(除了一些例外情况,例如使用参数时),但是单个 DAX 公式就可以同时提供多个不同的结果,具体取决于您使用它的位置和方式,也就是:上下文。
同时,上下文也是使用 DAX 实现一些高级应用的关键。当你跨过了经常犯一些低级错误的菜鸟阶段(如不知道要使用哪些 DAX函数、语法不正确或忘记括号等)之后,你在使用 DAX 时可能要天天和上下文打交道。
我们甚至会说:DAX 中的每一个问题都来自于上下文,并且所有问题的解决方案都是通过仔细审视上下文找到的。
这种说法很少会被否定!
在本章中,我们将讨论一些有关上下文的基本主题,这些主题是理解本书第二部分所有内容的必要条件。本章主要涵盖如下内容。
• DAX 上下文简介
• DAX 筛选:使用 CALCULATE 函数
• 时间智能函数
• 改变关系的行为
• DAX 中的表函数
• 使用表函数进行筛选
• DAX 变量
由于本书第二部分的各个章节会深入演示 DAX 上下文的各个方面,因此本章将相对较少地展现示例。
4.1 Power BI 模型
本章中的示例取自一个简单的 Power BI 模型。该模型由一个事实数据表 fSales 和一些筛选表组成:
图4.1 示例 Power BI 模型
本章的模型文件 1.4 上下文和筛选 pbix 。如需下载请关注公众号:PowerBI生命管理大师学谦,回复关键字“dax”。
4.2 DAX 上下文介绍
DAX 上下文的通用术语是计值上下文(evaluation context):DAX 公式在上下文中计算,从而得到特定的结果。我们将上下文分为以下三种类型。
• 行上下文
• 查询上下文
• 筛选上下文
在大多数 Power BI 文档和出版物中,只涉及两种类型的上下文:行上下文和筛选上下文。查询上下文这一术语在 Power BI 问世之前就已经出现在 Excel 里的 Power Pivot 中了(没错,那会我们就开始在使用了),并且我们一直在使用它。根据我们在 DAX 课程授课中的经验,区分查询上下文和筛选上下文有助于大家理解更复杂的应用场景。
以下展开讨论每一种上下文类型。
4.2.1 行上下文
行上下文是创建计算列时会用到的上下文类型。定义计算列的 DAX 公式在表中的每一行分别计算一次。计算结果通常特定于对应的行。原因是,同一表中其他列中的值被用在计算中,而这些值在每行中一般是不同的。例如,在 fSales 表(销售表)中创建一个用于计算 SalesAmount(销售额)和 Costs(成本)之间差额的计算列,定义为 Margin(利润),代码如下。
Margin = fSales[SalesAmount] – fSales[Costs]
由于直接引用了列,您可能立即意识到这个公式用于计算列。此类计算只能在行上下文中完成,这是行上下文与其他上下文类型的主要区别。(在简单的计算列公式中,fSales 这样的表前缀通常被省略。)
注意,在计算列中直接对某些列进行引用时,只能对当前计算所在的行上的列值起作用,如果要从其他行中检索值,您需要采用完全不同的方法。这与 Excel 中的计算完全不同。在 Excel 中,从“上面的行”中获取一个值是很常见的。当你意识到 Power BI 模型表中的行之间没有严格的顺序时,就很容易理解这个问题了。
只有少数 DAX 函数专门用于在行上下文中工作。如果包含计算列的表与另一个表相关,则在每行中,可以使用 RELATED 函数从另一个表中的列中检索相应的值。下面的公式利用 fSales 表中的 OrderDate 列(订单日期列) 和 Date 表(日期表)中的 Date 列(日期列)之间的关系来检索每行所对应的年份。
Year = RELATED('Date'[Year])
图4.2展示了以上公式的计算结果: fSales 表中的 Year(年份)列。
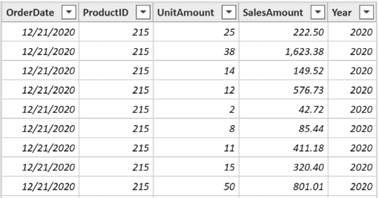
图4.2 添加 Year 计算列(为便于阅读,删除了部分列)
在使用 RELATED 函数时要注意一个限制条件:关系的另一端必须是“一”端,也就是说,另一个表(在此示例中为 Date 表)中的相应的列必须具有唯一值。毕竟,公式的结果需要产生单个值。
当关系的基数反转时,可以使用 RELATEDTABLE 函数。例如,要向 Date 表中添加一个计算列,其中包含每天的销售交易记录数,则下面的公式可以实现。
Number of Transactions = COUNTROWS(RELATEDTABLE(fSales))
对于 Date 表中的每一行,RELATEDTABLE 函数都会生成与之相关的fSales表中的一系列行的集合。由于生成的结果是一个表,不能直接用作计算列中的值,因此我们使用了 COUNTROWS 来简单地计算该表中的行数。
尽管 RELATEDTABLE 专门用于行上下文,但它与 RELATED 的根本不同之处在于它在背后会使用不同的上下文类型。
|  | 如第 3 章“DAX的用法”中所述,我们不鼓励使用计算列。这并不意味着您不必处理行上下文。行上下文在 DAX 表函数中也起着重要作用。本章稍后将对此进行详细介绍。 |
| ———————————————————— | ———————————————————— |
| 如第 3 章“DAX的用法”中所述,我们不鼓励使用计算列。这并不意味着您不必处理行上下文。行上下文在 DAX 表函数中也起着重要作用。本章稍后将对此进行详细介绍。 |
| ———————————————————— | ———————————————————— |
OK!让我们继续其他的上下文类型学习之旅。在我们讨论了查询上下文和筛选上下文之后,就可以清楚地阐述行上下文的一些特殊性了。
4.2.2 查询上下文
在使用 DAX 度量值时我们会用到查询上下文。与之前的行上下文类似,查询上下文使得 DAX 度量值返回特定的结果。当然,不同之处在于,我们不是在单个表的内部展开工作。简而言之,查询上下文是指在 Power BI 模型中选择的行的集合,基于这个集合进行 DAX 公式的计算。恰当地区分查询上下文中两个密切相关但独立的元素是很有必要的。
• 选定内容(selection)是指模型中各个表中在特定上下文中选择的行的集合。
• 筛选器(Filters)是导致选择行的原因。
在查询上下文中,筛选器来自于 Power BI 报表中的元素。它们有多种类型:切片器、筛选器窗格中的筛选器、视觉对象中的标签或其他视觉对象中的选定项。以上所述任何一个都会在列上形成特定的规则;例如,在图4.3中,切片器在 Year 列上引发筛选器:年份等于2019。不同列上可以有许多筛选器,甚至同一列上也可能有多个筛选器。所有这些筛选器共同确定在每个表中选择哪些行:同时满足每个筛选规则的所有行。
| | 第 6 章 “自动存在”中对视觉对象筛选器进行了全面的讨论。 |
| ———————————————————— | —————————————————— |
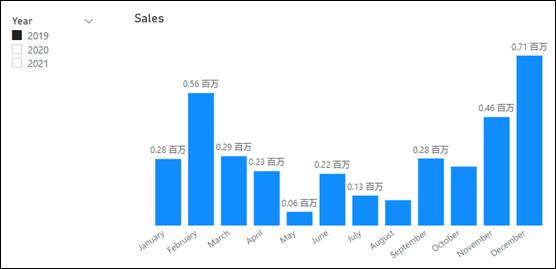
图4.3 一个简单的 Power BI 报表
在查询上下文中,表之间的关系起着重要作用:筛选器传递。这意味着,一个表中某一列的筛选器可以通过关系的交叉筛选方向传递到另一个表,如图4.4所示。
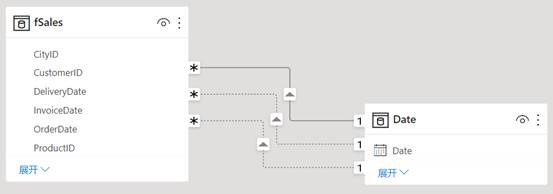
图4.4 筛选器沿着关系上的箭头方向传递
严格地说,传递的其实不是筛选器本身,而是筛选器的效果:在相关联的表中,只有那些满足筛选规则的行所对应的行才会被选择。当然,这正是我们想要的结果:当切片器设置为图4.3所示的2019年时,我们希望看到2019年的结果,这意味着所有计算都只能在事实表中与2019年的日期相对应的行上进行。
由于查询上下文的性质,我们不能像在行上下文中那样在公式中直接使用列。以下公式作为度量,不被编辑器接受:
Report Year = 'Date'[Year]
这会导致一条错误消息:无法确定表 ‘Date’ 中列 ‘Year’ 的单个值。当度量公式引用包含许多值的列,且未指定用于获取单一结果的 min、max、count 或 sum 等聚合时,可能发生这种情况。从概念上讲,原因是所选内容有可能包含多个值。即使列仅包含一个唯一值,或者当表仅包含一行时,也是如此。
4.2.3 筛选上下文
筛选上下文看起来类似于查询上下文,但有一个重要的区别:筛选上下文是由 DAX 代码更改的上下文,比如可以在查询上下文中添加或更改筛选器。在此过程中起到核心作用的 DAX 函数是 CALCULATE(或与其同级的 CALCULATETABLE)。使用 CALCULATE 更改上下文的方式将在本章后面的 DAX 筛选:使用 CALCULATE 部分中深入讨论。
查询上下文可以直接通过视觉对象看到,但是筛选上下文是不能直接看到的,因此筛选上下文看起来要难一些。使用筛选上下文需要一定的抽象思维能力,并仔细地分析在特定情况下哪些筛选器处于活动状态。出于同样的原因,有些使用筛选上下文创建的度量值可能会给报表使用者造成疑惑,因此在创建度量值的时候应谨慎一些,例如,使用一目了然的度量值名称。
能够对上下文进行修改,为 DAX 的应用开辟了大量的可能性,而这些可能性仅通过行上下文和查询上下文是无法实现的。它可以给我们提供与查询上下文不对应的结果,并且可用于提供高级见解,例如将产品的销售额与所有产品的销售额进行比较,将今年的销售额与去年同期进行比较,推断未来的趋势,等等。事实上,如果没有筛选上下文,本书第二部分所讨论的所有方案都是不可能实现的。
使用 DAX 创建复杂见解的一般过程可以描述如下。
-
分析研究将在接下来的计算中使用到的(可能的)查询上下文。
-
确定期望结果所需的筛选上下文。
-
确定如何从查询上下文变为筛选上下文。
想要驾驭 DAX,您应该熟悉这种思维方式,这与使用 SQL 检索数据、编程或在 Excel 中执行计算有着根本的不同。
4.2.4 检查筛选器
计值上下文中的筛选器会在模型的表中选择某些特定的行。当您考虑这对单个列的影响时,可能会有以下几种情况。有可能并没有进行任何选择,使得列中的所有值都在上下文中。也可能是选择了值的子集,这可能是由该列上的筛选器引起的,在这种情况下,我们定义该列是被直接筛选(Directly Filtered)的。或者它可能是由同一表中另一列的筛选器或另一个表中的筛选器通过关系传递引起的。对于后者,无论筛选器来自哪里,我们都定义该列是间接筛选(Indirectly Filtered)或交叉筛选(Cross Filtered)的。
DAX 包含许多用于检查上下文中的筛选器及其效果的函数。每个函数都将某一列(例如列 A)作为参数。
• ISFILTERED:检查列A否有直接筛选器。
• ISCROSSFILTERED:检查模型中任何列上的筛选器是否会导致列A中的筛选。
• HASONEFILTER:检查列A上的直接筛选器是否只选择了一个值。
• HASONEVALUE:检查模型中任何列的筛选是否会导致在列A中恰好选择一个值。
• ISINSCOPE:检查由于视觉对象内部的列 A 上的筛选器是否导致列A中只选择了一个值。此功能旨在检测允许向下钻取的视觉对象中的当前钻取级别。
如果您想查看具体的上下文的内容,这些函数可能会有所帮助。它们还可用于实现特定的 DAX 度量值行为,尽管在此过程中存在一些陷阱。您可以在第5章使用 DAX 构建安全性中找到一些示例。
4.2.5 比较查询和筛选上下文与行上下文
既然我们已经介绍了查询和筛选上下文,那么我们就可以从另一个角度来认识行上下文了。例如,假设您在 fSales 表中创建了一个计算列,公式如下。
TotalTax = SUM(fSales[Tax])
您会发现,在生成的 TotalTax 列(总税额列)中,每行都包含相同的值。SUM 函数计算表中所有行的总和,即使我们处于单个行的行上下文中也是如此。对于 DAX 初学者来说,这通常是一个令人惊讶的发现。让我们看另一个示例,这次是 Date 表中的计算列:
TotalShipping = SUM(fSales[ShippingCosts])
同样,您将在每行中找到相同的结果,即使 fSales 表和 Date 表之间存在关系也是如此。这种关系难道不应该对每天的总运费进行计算然后单独返回每一天的值吗?
以上这些示例向我们揭示了行上下文的本质。TotalShipping 示例表明在行上下文中,关系不会传递筛选。这是一个非常有用的经验法则,不过现实情况要更加微妙一些。在行上下文中,DAX 只允许使用同一表中的列值,除此之外,不会选择或筛选任何内容。在计算列中,表中任何列上都没有筛选器。因此,关系无法进行传递。这意味着,当您引用另一个表时(如 TotalShipping 计算),您将使用完整的一张表。即使您引用了计算列所在的表,例如总税计算,也会使用所有的行。
因此,如果您正在使用行上下文,但需要关系进行传递,则必须找到一种方法将行上下文转换为筛选上下文。为此,您必须使用 CALCULATE 函数。
4.3 DAX 筛选:使用 CALCULATE
转换上下文是 DAX 最强大的功能之一。用于上下文转换(context transformation)的 CALCULATE 函数是当之无愧的最重要的 DAX 函数。通过在 CALCULATE 中指定筛选器表达式,可以控制公式所处理的行的子集。这可以通过添加或替换筛选器来完成,也可以通过从上下文中删除筛选器来完成。由于关系可以通过筛选器传递在上下文中起重要作用,因此激活或停用关系或更改其筛选器传递行为也是上下文转换的一种形式。
让我们从一个示例 DAX 度量值开始,代码如下。
SalesLargeUnitAmount =
CALCULATE(
SUM(fSales[SalesAmount]),
fSales[UnitAmount] > 25
)
此度量值返回已售出超过 25 个单位的交易记录的销售额。CALCULATE 的第一个参数是要执行的计算,在本例中为 fSales 表中 SalesAmount 列的总和。所有其他的参数(可能有很多)都是筛选器参数。
|  | 如果一个 CALCULATE 简单计算过程在单独的一个度量值中,DAX 允许您无需显式地使用 CALCULATE 函数。比如可以写一个简单的sales(销售额)度量值,代码如下。 Sales = SUM(fSales[SalesAmount]) 我们之前看到的示例度量值也可以重新写为: SalesLargeUnitAmount = [Sales] (fSales[UnitAmount] > 25) 不过,我们建议不要使用这种语法,因为使用显式 CALCULATE 的公式可读性更强,尤其是在一些更复杂的公式中。 |
| ———————————————————— | ———————————————————— |
| 如果一个 CALCULATE 简单计算过程在单独的一个度量值中,DAX 允许您无需显式地使用 CALCULATE 函数。比如可以写一个简单的sales(销售额)度量值,代码如下。 Sales = SUM(fSales[SalesAmount]) 我们之前看到的示例度量值也可以重新写为: SalesLargeUnitAmount = [Sales] (fSales[UnitAmount] > 25) 不过,我们建议不要使用这种语法,因为使用显式 CALCULATE 的公式可读性更强,尤其是在一些更复杂的公式中。 |
| ———————————————————— | ———————————————————— |
想要透彻理解 CALCULATE 的工作原理,应该时刻牢记它按顺序执行四个基本步骤。
-
将现有上下文(行上下文或查询上下文,或其他筛选上下文)全部转换为筛选上下文。
-
筛选器参数中引用的列(或整个表)上,如果有筛选器,那么这些筛选器将被删除。
-
添加新的筛选器。
-
在新的筛选上下文中计算第一个参数中的表达式。
有几个特定的 DAX 函数可以放在筛选器参数中使用,从而改变以上的过程。但是一口吃不成胖子,让我们暂时先关注以上这些步骤罢,以 SalesLargeUnitAmount 度量值为例。
4.3.1 步骤 1:设置筛选上下文
使用 CALCULATE 时,首先要做的是创建一个可以更改筛选器的环境。如果从查询上下文或筛选上下文开始,这意味着我们已经拥有了环境,所以没什么可做的。因此,对于 SalesLargeUnitAmount 度量值来说,这个过程微不足道。但是,如果我们使用行上下文,那么情况就变得很不同了。
从行上下文到筛选上下文的转换,是通过对表中的每一列创建一个筛选器来实现的,这些筛选器将对应的列中的值指定为当前行中的列的值(请记住,行上下文始终与单个行相关)。结果是生成了一个选择当前行的筛选上下文。除此之外,如果此表与其他表之间存在关系,则这些关系将会传递这些筛选,此时我们也得到在其他表中由被筛选的行所构成的子集。
例如,我们可以通过将之前使用的 TotalTax 计算列用 CALCULATE 包裹起来改一下该列的公式(请注意,我们在这里使用不带任何筛选器参数的 CALCULATE),代码如下。
TotalTax2 = CALCULATE(SUM(fSales[Tax]))
以上公式将每一行中的行上下文都转换为筛选上下文。SUM 函数现在只适用于所选的行,也就是只有当前行[1]。换句话说,结果只是行本身中 Tax 列的值。
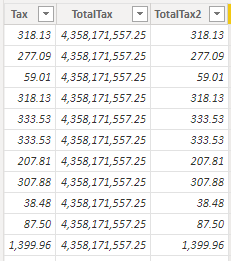
图4.5 计算列中 CALCULATE 的效果
在 TotalShipping 这个例子中的计算列,在 Date 表中,会发生同样的事情,代码如下。
TotalShipping = CALCULATE(SUM(fSales[ShippingCosts]))
Date 表中的行上下文将转换为筛选上下文,该筛选上下文对表的每一列都具有筛选作用。这一次,fSales 和 Date 表之间的关系可以传递所选内容,从而导致 fSales 表中与 Date 表中的当前行相对应的行集被筛选,如图4.6所示。
图4.6 CALCULATE 导致关系传递筛选器
添加了 CALCULATE 的结果就是我们得到了正确的每天的 TotalShipping 数量。
|  | 您可能会猜测有多少实际场景中会使用不带筛选器参数的 CALCULATE,这样做的频率比您想象的要高。每次在公式中调用度量值时,CALCULATE 都会隐式地出现,例如: SalesByCustomer = DIVIDE([Sales], [Number of Customers]) 在这个公式中,”销售额”和”客户数”的计算都是在筛选上下文中完成的。调用度量值是将行上下文转为筛选上下文的常用方法,这是您经常需要执行的操作。 |
| ———————————————————— | ———————————————————— |
| 您可能会猜测有多少实际场景中会使用不带筛选器参数的 CALCULATE,这样做的频率比您想象的要高。每次在公式中调用度量值时,CALCULATE 都会隐式地出现,例如: SalesByCustomer = DIVIDE([Sales], [Number of Customers]) 在这个公式中,”销售额”和”客户数”的计算都是在筛选上下文中完成的。调用度量值是将行上下文转为筛选上下文的常用方法,这是您经常需要执行的操作。 |
| ———————————————————— | ———————————————————— |
好了,初始筛选上下文已就绪, CALCULATE 可以执行下一步操作了。
4.3.2 步骤 2:删除现有筛选器
CALCULATE 工作顺序中的第二步是从新的筛选上下文中删除筛选器。该过程非常简单:检查其中一个筛选器参数中引用的每个列的筛选器。如果该列上存在筛选器,则会将其删除。
在我们的示例 SalesLargeUnitAmount 度量值中,单个筛选器参数如下。
fSales[UnitAmount] > 25
此筛选器参数导致 CALCULATE 删除 fSales[UnitAmount] 列上的所有筛选器。
有时容易被疏忽的一点是,筛选器参数中未涉及的列会继续保留其筛选器(如果存在)。由于无法完全控制原始上下文的外观,因此在查看度量值可能用于的不同方案时应小心。您可能需要移除比最初预期的更多的筛选器。在您使用DAX的过程中,总会遇到这样的场景,在我们完成所有四个步骤后,其他筛选器可能还会产生影响。
步骤 2 中 CALCULATE 的行为可以通过使用 KEEPFILTERS 函数进行更改。此函数会导致 CALCULATE 对应用 KEEPFILTERS 的筛选器参数跳过步骤 2,例如以下的代码。
SalesLargeUnitAmount KeepFilters =
CALCULATE(
[Sales],
KEEPFILTERS(fSales[UnitAmount] > 25)
)
在此公式中,只要 UnitAmount 列上有现有筛选器,就会保留该筛选器,并在步骤 3 中添加一个新的筛选器。
4.3.3 步骤 3:应用新筛选器
CALCULATE 执行的第三步是应用新的筛选器。与步骤 2 一样,该函数遍历其筛选器参数,并将其作为创建新筛选器的说明。在以上示例中,以下的筛选器参数将导致在 UnitAmount 列上创建新的筛选器,选择所有大于 25 的值。
fSales[UnitAmount] > 25
在理解 CALCULATE 时,记住步骤 2 和步骤 3 按该顺序应用是非常有帮助的。筛选器参数本身的顺序无关紧要,如下是一个简单的例子。
Sales373_374 =
CALCULATE(
[Sales],
Products[ProductID] = 373,
Products[ProductID] = 374
)
许多 DAX 初学者都觉得此公式返回产品ID为 374 的销售额,理由是 ProductID 筛选器首先设置为373,然后又设置为374。实际上,此度量值将始终返回空白,因为是在 ProductID 这一列上添加了两个筛选器,这要求该列同时等于 373 和 374。Products表(产品表)中没有满足这些规则的行,因此 TotalSales 度量值将返回一个空白值(假设存在一个将筛选器从 Products 表传递到 fSales 表的关系)。
您可能会认为这是一个微不足道的例子。但是,稍微改变一下形式,它就会愚弄许多人,请看下面的代码。
Sales373OrWhat =
CALCULATE(
[Sales],
Products[ProductID] = 373,
ALL(Products)
)
与前面的示例一样,深入理解整个过程发生了什么的正确方法是意识到在添加新筛选器之前每个筛选器参数的筛选器都被移除了。结果是 ProductID 为373的销售额。
4.3.4 步骤 4:对表达式进行计算
CALCULATE 工作顺序的最后一步很简单:在设置完筛选上下文、删除筛选器并添加新筛选器之后,我们就可以在新的上下文中计算第一个参数中的表达式了。当然,实践是检验真理的唯一标准,因为这是我们可以真正看到所有上下文转换的效果的地方。
作为筛选器操作如何棘手的示例,请以下面的矩阵视觉对象为例。
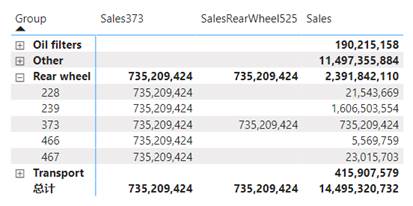
图4.7 示例度量值的输出结果
在此矩阵中,我们使用 Group 列(组列)和 ProductID 列(产品ID列)作为标签来显示有关产品的信息。我们特别关注 Rear wheel 组(后轮组)中的编号为373的产品。在 Product 列(产品列)中此产品的名称是REAR WHEEL STEEL #525(后轮钢#525)。我们希望能够将每个产品的销售额与产品 373 的销售额进行比较。您可以将其视为产品373是我们公司最具战略意义的产品,我们希望将每个产品的销售额表示为产品373销售额的百分比。
若要进行比较,我们需要一个计算,该计算在视觉对象的每一行中都会返回产品 373 的销售额。我们使用两个度量来尝试:
Sales373 =
CALCULATE(
[Sales],
Products[ProductID] = 373
)
以及:
SalesRearWheel525 =
CALCULATE(
[Sales],
Products[Product] = "REAR WHEEL STEEL #525"
)
Sales 度量值同样位于视觉对象中,因此可以更好地查看到底发生了什么。在该视觉对象中的大多数行中,查询上下文中存在两个筛选器:一个位于 Group 列上,另一个位于 ProductID 列上。例外情况是小计行(只有 Group 级别的筛选器)和总计行(没有筛选器)。
显然,使用 CALCULATE 计算的两个度量值返回了不同的结果。为什么会有这种差异呢?由于 Sales373 度量值在筛选器参数中使用了 ProductID 列,因此在添加新的筛选器(步骤 3)之前,将删除该列上的任何现有筛选器(步骤 2)。比如,该视觉对象的产品239这一行上,将删除筛选器“ProductID 等于239”,并添加筛选器“ProductID 等于373”。因此,计算返回了产品373的销售额。
SalesRearWheel525 度量值就不是这种情况了。此处,筛选器参数引用的是 Product 列,因此将删除 Product 列上的任何现有筛选器(步骤 2)。在这之后,添加新的筛选器(步骤 3)。再次查看产品239,查询上下文包含对 Group 和 ProductID 的筛选器。该度量值不会删除这些筛选器,而是在 Product 列上添加新的筛选器。导致的结果就是筛选上下文是 Product 表中满足三个筛选条件的所有行;很显然,除非三个筛选器恰好都指向同一产品,否则不会有任何行被选择,也就是结果为空。三个筛选器恰好都指向同一产品的情况仅适用于产品373本身,也就是为什么视觉对象中只显示了一行数据。
相同的推理过程也可以解释为什么 Sales373 度量值不会在 Rear wheel 以外的组中返回结果:当 Group 上的筛选器选择另一个组时,其与 ProductID 373(新添加的筛选器)组合会导致 Product 表上的选择为空。
4.3.5 使用ALL函数清除筛选器
上一节中的两个度量值都存在着相同的问题,很明显,它们都依赖于上下文。若要创建一个无论在查询上下文中选择了什么产品都会始终返回产品 373 销售额的度量值,我们必须摆脱任何可能产生影响的筛选器。
精确控制要移除哪些筛选器非常重要。为此,可以使用一类 DAX 函数,我们将其称为 ALL 系列函数。这些函数之间的区别在于删除了哪些筛选器。
• ALL:此函数可以将一个或多个列或者是一个表作为参数。它会从指定的列中删除筛选器,或者从引用的表中的所有列中删除筛选器。如果确实需要,可以使用不带参数的 ALL 从整个 Power BI 模型中删除所有筛选器。以上情况,代码如下。
ALL(Cities[Country])
ALL(Cities[Country], Cities[State])
ALL(Cities)
ALL()
|  | 对表使用 ALL 时,从中删除筛选器的列包括相关表中的列。例如,当 fSales 表和 Cities 表之间存在多对一关系时,ALL(fSales) 也会从 Cities 表中删除筛选器。另见ALLCROSSFILTERED。 |
| ———————————————————— | ———————————————————— |
| 对表使用 ALL 时,从中删除筛选器的列包括相关表中的列。例如,当 fSales 表和 Cities 表之间存在多对一关系时,ALL(fSales) 也会从 Cities 表中删除筛选器。另见ALLCROSSFILTERED。 |
| ———————————————————— | ———————————————————— |
• ALLEXCEPT:此函数可用作 ALL 的替代函数,它可以有许多列参数。您可以指定一个表以及该表中想要保留筛选的列,而不是将所有想要删除筛选器的列都写一遍。该函数可以删除表中所有其他列中的筛选器,如下所示。
ALLEXCEPT(Cities, Cities[Country])
• ALLNOBLANKROW:使用 ALL 时,生成的上下文将包含指定列中的所有值。这可能会包含由于不完整关系而添加到表中的空白行中的值(请参见第2章 模型设计;这些值必然为空)。如果不希望这些空白值包含在上下文中,则应使用 ALLNOBLANKROW 而不是 ALL。此函数采用一个参数,一列或一个表,如下所示。
ALLNOBLANKROW(Cities[Country])
• ALLSELECTED:这是一个特殊的 ALL 函数,因为它是唯一需要关注筛选器来源的函数。只有当筛选器来自于使用度量值的视觉对象中的标签时,ALLSELECTED 才会删除这些筛选器。而来自切片器、页面筛选器或其他视觉效果的外部筛选器则保持不变。此函数用于创建聚合视觉对象中所选项的度量值,例如,在一个视觉对象中的总计行上总是呈现100%。该函数可以使用一个表、一列或多列作为参数,甚至可以像ALL一样没有参数,举例如下。
ALLSELECTED(Cities[Country])
ALLSELECTED (Cities[Country], Cities[State])
ALLSELECTED ()
• ALLCROSSFILTERED:引入此函数是为了在 Power BI 复合模型中,或包含 Direct Query 和导入表的组合的模型,或不同的 Direct Query 连接使用。在此类模型中,不同来源的表之间的关系是“弱关系”,并且并不会按照标准的行为:当 fSales 表是 Direct Query 模式而 Cities 表是导入模式时,ALL(fSales) 不会从 Cities 表中删除筛选器。这时候就需要用到 ALLCROSSFILTERED 函数了,它将表引用作为参数,并将从该表和相关的表中删除筛选器,即使它们之间是弱关系也是如此。在标准的导入模型中,不需要使用 ALLCROSSFILTERED。函数用法如下。
ALLCROSSFILTERED(fSales)
|  | 您可以使用另一个 DAX 函数来删除 CALCULATE 语句中的筛选器:REMOVEFILTERS。此函数将一个或多个列或整个表作为参数,例如: CALCULATE( [Sales], REMOVEFILTERS(Cities) ) 此函数是作为 ALL 的更易于理解的替代函数而引入的。我们更喜欢较短的 ALL,并且从不使用 REMOVEFILTERS。 |
| ———————————————————— | ———————————————————— |
| 您可以使用另一个 DAX 函数来删除 CALCULATE 语句中的筛选器:REMOVEFILTERS。此函数将一个或多个列或整个表作为参数,例如: CALCULATE( [Sales], REMOVEFILTERS(Cities) ) 此函数是作为 ALL 的更易于理解的替代函数而引入的。我们更喜欢较短的 ALL,并且从不使用 REMOVEFILTERS。 |
| ———————————————————— | ———————————————————— |
通过认真选择一个或多个 ALL 函数,您可以让 CALCULATE 完全按照自己的意愿执行操作。请记住,我们希望创建一个始终返回产品 373 销售额的度量值;换句话说,我们确切地知道我们想要的筛选上下文是什么样子。我们无法控制开始时使用的查询上下文中存在哪些筛选器,但可以控制删除哪些筛选器。请查看以下更新的度量值。
SalesRearWheel525_ALL =
CALCULATE(
[Sales],
Products[Product] = "REAR WHEEL STEEL #525",
ALL(Products)
)
通过使用此公式,在将筛选器添加到 Product 列之前,将删除 Products 表中的任何现有筛选器。区别显而易见,如图4.8所示。
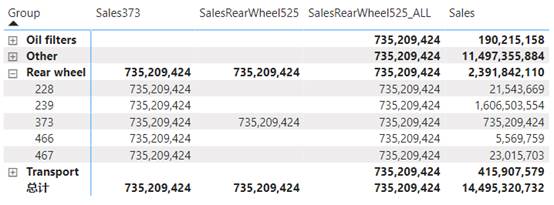
图4.8 使用 ALL
我们可以看到,不仅在 Rear wheel 这一组里所有的产品都返回了产品 373(即REAR WHEEL STEEL #525)的结果,甚至在查询上下文筛选其他产品组时也返回了相同的结果。有了这个,我们就可以表示任何产品相对于产品373的销售比例了,简单的代码如下。
Sales% = DIVIDE([Sales], [SalesRearWheel525_ALL]
通过对筛选参数和 ALL 函数进行组合,可以创建相当多的功能强大的 DAX 度量值。不过,仍然有一些筛选器难以创建和指定,其中就包括处理日历的筛选器。这就是 DAX 包含了用于此目的的一类特殊函数的原因,接下来我们就对此展开讨论。
4.4 时间智能
几乎所有的 Power BI 模型都会包含一些有关时间的分析。例如,我们希望将当前的结果与去年同期进行比较。可能还需要许多其他与日历相关的见解,例如年初至今(year-to-date)的结果、滚动总计或过去任何其他时间段的增长率。困难在于公历相当混乱:大多数年份有365天,但有些年份有366天,就月份而言,少则28天,多则31天不等。
尽管这些日历很复杂,但基于日历的分析只是筛选以更改上下文。请考虑如图4.9所示的年初至今的销售图表。
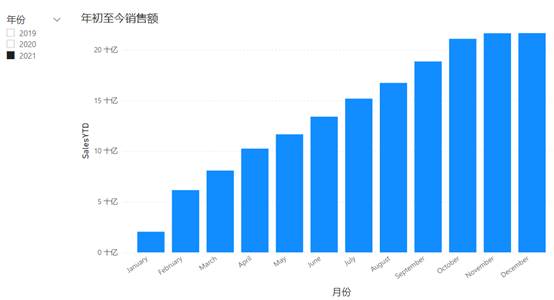
图4.9 一个展示年初至今销售额的图表
根据年初至今的定义,您在 August(八月)这一列中看到的是 2021 年 1 月 1 日至 2021 年 8 月 31 日期间的总销售额。但是,此列的查询上下文包含对年份 (2021) 和月份 (8 月) 的筛选,从而导致选择了 2021 年 8 月 1 日至 8 月 31 日这个时间段。显然,必须在此过程中修改上下文,才能够返回年初至今的总销售额。
因此,在年初至今销售额的计算中,您可能会期望使用带着筛选参数的 CALCULATE 来解决,思路如下。
SalesYTD =
CALCULATE(
[Sales],
... (some filter argument)
)
实际上,DAX 时间智能函数在 CALCULATE 中通过筛选参数来处理日历的复杂性。年初至今筛选器由 DATESYTD 函数提供,代码如下。
SalesYTD =
CALCULATE(
[Sales],
DATESYTD('Date'[Date])
)
DATESYTD 函数基于日期表上的查询上下文工作。其整个工作过程按照如下所述。
-
检索上下文中最新的日期。
-
确定此日期所在的年份以及该年的第一天。
-
在 Date 表 [Date] 列上创建一个筛选器,选择上下文中从这一年的第一天到最后一天的所有日期。
通过使用新的上下文,CALCULATE 可以完成其计算工作,在我们的示例中,对销售度量值进行计算。但是等等:DATESYTD 筛选器参数引用的是 Date 列,但在图 4.9 中的图表对象中,Year 列和 Month 列上有筛选器!这是一个非常普遍的情况,因此,DATESYTD 还有一个步骤。
- 添加隐式 ALL(’Date’) 筛选器参数。
最后一步是所有时间智能函数所共有的,这样我们就不必在使用这些函数时添加显式的 ALL 函数了。
| | 只有当你正式地将表标记为 Power BI 模型的日期表时,或者在数据类型为 Date 的列上创建从事实表到日期表的关系时,才会添加隐式 ALL(‘Date’ [Date]) 子句。尽管时间智能函数可以在没有正式声明日期表的情况下正常工作,但我们强烈建议您仍然使用此声明。 |
| ———————————————————— | ———————————————————— |
如前所述,时间智能是一个非常普遍的需求。因此,一些时间智能函数也提供了更短、更易于使用的版本。与 CALCULATE 搭配使用的 DATESYTD 函数可替换为一个单独的 TOTALYTD 函数,代码如下。
SalesYTD_short =
TOTALYTD(
[Sales],
'Date'[Date]
)
尽管语法不同,但是这个公式在本质上与使用 DATESYTD 函数的公式完全相同。虽然这可能是一个优势,但缺点也很明显,对于许多 DAX 初学者来说,此函数看起来像是只能计算年初至今的总计。实际上,TOTALYTD 所做的唯一的一件事就是改变上下文。它可以返回年初至今的平均值或年初至今的任何想要计算的内容;这完全取决于第一个参数里的度量值或表达式。
| | 财年,一般不将 1 月 1 日作为一年的第一天,为了应用场景的完整性, DATESYTD 和 TOTALYTD 同样适用于这样的日历表。DATESYTD 允许使用第二个参数,它应该能够从中确定一年中的某一天,例如”8/31”或”2020/9/30”;这被视为一年中的最后一天。不过,有一点我们从未真正理解过,那就是在TOTALYTD中,这个参数是第四个参数,这意味着你必须填入第三个参数。这是一个可选的附加筛选器。您可以在此处放心地使用 ALL(’Date’[Date]),因为无论如何它都会被隐式添加的。 |
| ———————————————————— | ———————————————————— |
DATESYTD 是众多时间智能函数当中使用最多的一个,还有几个频繁使用的,我们简单做一下介绍。
• SAMEPERIODLASTYEAR:顾名思义,该函数采用当前上下文并将其向后移动一年。当然,这是计算同比增长数字所需要的。奇怪的是,该功能没有快捷方式版本。去年的销售额可以通过以下代码来计算。
SalesLY =
CALCULATE(
[Sales],
SAMEPERIODLASTYEAR('Date'[Date])
)
• DATEINPERIOD:此函数可用于返回从某个参考日期开始(或结束)的周期,其指定长度以天、月、季度或年为单位表示。这是计算滚动总计所需的函数。例如,使用以下公式计算12个月的滚动销售总额(即回溯12个月)。此处,MAX(’Date’ [Date]) 用于检索上下文中的最后一天作为参考日期。
SalesRollingTotal =
CALCULATE(
[Sales],
DATESINPERIOD(
'Date'[Date],
MAX('Date'[Date]),
-12, MONTH
)
)
使用时间智能函数时,请务必记住,每次时间智能函数都会转换日期表上的上下文;除此之外,时间智能函数不会有任何其他作用。这意味着模型中与日期表无关的任何表都不会受到此上下文转换的影响。同时,这也意味着,当您的日期表太“短”时,您可能会得到并非您所期望的结果。例如,如果您的日期表开始于 2020 年,并且您在 2020 年 2 月的日期上下文中使用 SAMEPERIODLASTYEAR 函数,则上下文结果一定为空。这将导致度量值的结果为空,即使你聚合的事实表中确实存在着 2019 年或更早的日期。
4.5 改变关系的行为
在 第2章 模型设计 中我们介绍过,两个表之间可以建立多个直接关系,但其中只有一个关系可以是活动的。表之间的间接关系路径也是如此:Power BI 模型只允许在模型中的任意两个表之间有一个活动路径。当然,只有当你需要时可以激活这些非活动关系时,这才有用。您可以使用 USERELATIONSHIP 函数来执行此操作。
函数 USERELATIONSHIP 是作为 CALCULATE 中的筛选器参数来使用的。不知道你是否会感到奇怪,USERELATIONSHIP 字面意思是“使用关系”,而 CALCULATE 中的筛选器参数需要表或表表达式,这两者看上去不搭边,但它确实是有道理的。举个例子,某个事实表和筛选表之间的当前活动关系可以将筛选表中的选择传递到事实表中。激活另一个关系意味着,当前所选内容传递到事实表上时会筛选事实表中的不同行。换句话说:激活另一个关系意味着更改计算的上下文。而改变上下文自然要用到 CALCULATE。
USERELATIONSHIP 函数需要两个参数,是对想要激活的关系的两端的列引用。例如,如果 fSales 和 Date 表之间的活动关系位于 fSales[OrderDate] 上,如果希望改用fSales[InvoiceDate]来建立关系,那么代码如下。
TotalInvoiced =
CALCULATE(
[Sales],
USERELATIONSHIP(fSales[InvoiceDate], 'Date'[Date])
)
应该清楚的是,当您使用另一个关系时,计算结果的含义会发生变化。当 Sales 度量值返回订购的金额时,TotalInvoiced (发票总额)度量值返回已开票的金额。前者将被用于收入分析,而后者可能有助于现金流分析(其中实际付款的计算将是一个关键的补充)。当然,这取决于组织对实际销售的业务定义。
更改关系行为的另一种方法是更改活动关系的筛选器传递行为。用于此目的的 DAX 函数是 CROSSFILTER,它同样也是被用于 CALCULATE 中的筛选器参数。
与 USERELATIONSHIP 一样,CROSSFILTER 将关系中涉及的两列作为参数。第三个参数可以设置关系的筛选器传递方向或交叉筛选器类型。可以使用五种交叉筛选器类型。
• OneWay(单向):沿默认方向传递筛选器,从具有主(唯一)键的表到包含外(非唯一)键的表。
• Both(双向):在两个方向上传递筛选器。
• None(无):不传递筛选器。
• OneWay_LeftFiltersRight:沿一个方向传递筛选器,从第一个参数中的列传递到第二个参数中的列[2]。
• OneWay_RightFiltersLeft:沿一个方向传递筛选器,从第二个参数中的列传递到第一个参数中的列。
举一个使用 CROSSFILTER 的例子,假设您想知道有多少个state(州)的产品被销售。该模型包含 fSales 表(销售数据表)、Cities 表(城市表)和 Date 表(日期表)之间的关系:
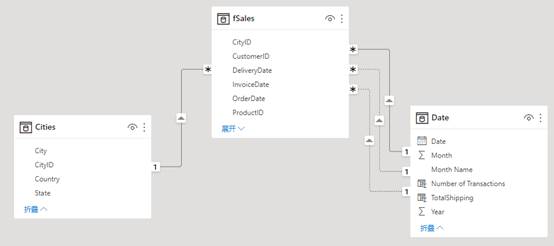
图4.10 各城市销售模型图
请注意,从模型图中可以看到,当我们选择了其中一个月,那么该月中的所有销售交易记录都将通过活动关系而被选择。但是,我们无法直接计算 state 的数量:Cities 和 fSales 之间的关系仅将筛选器从 Cities 传递到 fSales,而我们需要向另一个方向传递筛选器。在这种情况下,fSales 表中选定的行将传递选择 Cities 表中的相应行,然后我们就可以计算州的数量。
显然,必须改变关系的筛选器传递方向,DAX 公式如下。
StatesSoldTo =
CALCULATE(
DISTINCTCOUNT(Cities[State]),
CROSSFILTER(fSales[CityID], Cities[CityID], Both)
)
使用 DISTINCTCOUNT 函数可以对 State 列中的唯一值进行计数。但在完成此操作之前,CROSSFILTER 会根据在 fSales 表中选择的行来筛选 Cities 表中的行。
4.6 DAX 中的表函数
我们可以使用 SUM 和 AVERAGE 等基本聚合函数以及使用 CALCULATE 进行 DAX 筛选来实现许多计算过程。但是 DAX 语言能做的,远远不止这些。本部分将重点介绍表函数,表函数让我们可以更加从容地遨游在更高级 DAX 计算的海洋中。在本书的第二部分,您会发现我们所讨论的许多业务方案都涉及 DAX 表函数。
4.6.1 表聚合
首先,让我们看一个 DAX 中的简单聚合运算,请仔细看。
Sales1 = SUM(fSales[SalesAmount])
此公式中的 SUM 函数遍历 fSales 表,并从每行中检索 SalesAmount 列中的值。然后将所有这些值都加在一起,并提供最终结果。
 |
由于 Power BI 模型编码和存储数据的特殊方式(详见第2章 模型设计),因此从技术上讲,实际计算过程并不是这样。然而,从逻辑上讲,SUM就是这么做的,我们感兴趣的点也就在于这里。 |
|---|---|
现在,假设 SalesAmount(销售额)列是使用以下公式创建的计算列。
SalesAmount = fSales[UnitAmount] * fSales[SalesPrice]
由于 UnitAmount(数量)列和 SalesPrice(销售单价)列也在 fSales 表中,因此要问的一个有价值的问题是:我们可以在不使用 SalesAmount 列的情况下计算销售额吗?毕竟,我们强烈建议模型中不使用计算列。我们要进行的新计算同样需要遍历 fSales 表,但不应检索 SalesAmount 列中的值,而应从 UnitAmount 和 SalesPrice 列中分别获取数据,并逐个相乘。此处要使用的 DAX 函数是 SUMX,代码如下。
Sales2 =
SUMX(
fSales,
fSales[UnitAmount] * fSales[SalesPrice]
)
我们之前说过 SUM 函数只接受列引用作为其参数,SUMX 却需要提供一个表,即上面示例中的 fSales 表,第二个参数是要对表中每一行计算的表达式。我们称 SUMX 为表聚合函数;你可能还会遇到迭代器这个术语,比如 SUMX 在其第一个参数的表中进行迭代。
大多数基本聚合函数都有一个等效的表聚合函数,如 SUMX、AVERAGEX、MINX、MAXX、COUNTX、COUNTAX、PRODUCTX 和 CONCATENATEX。显而易见,表聚合函数可以通过函数名末尾的 X 来识别。还有一些鲜为人知的表聚合函数,包括像 MEDIANX,PERCENTILEX 和 STDEVX 这样的统计函数(最后两个函数有两种不同的用法,我们这里就不详细展开了,有兴趣的可以自行查阅官方函数说明)。
还有一些表聚合函数,如COUNTROWS,它返回表中的行数,并且没有等效的非表函数。还有 RANKX 是 RANK.EQ 的等效表聚合函数。
如果要去掉表中的计算列,上面的示例非常有参考价值。但是,表聚合函数的真正强大之处在于,您可以使用想要的任何表作为第一个参数。例如,假设您要创建一个返回每个城市的平均销售额的度量值。为此,不能在包含单个销售交易记录的 fSales 表上迭代,而应该迭代 Cities 表,代码如下。
SalesPerCity =
AVERAGEX(
Cities,
[Sales]
)
后续我们将讨论这个计算中究竟发生了什么,但让我们首先进一步详细说明可以使用的表。不仅模型中的任何表可以在表聚合函数中使用,甚至可以创建自己要想的特定的表来使用。我们将其称为虚拟表(我们本来想使用计算表这一术语,但是它早就被 Power BI 模型占用了)。
4.6.2 使用虚拟表
在上一节中,我们阐述过一个计算每个城市平均销售额的公式。现在,假设我们要计算每个州的平均销售额。与 SalesPerCity 度量值一样,我们需要一个每行对应一个州名的表,以便进行迭代。此表在模型中不容易立即获得,因为 State 只是 Cities 表中的列。因此,我们必须自己构造此表。尽管在这种简单的情况下,我们可以向模型中添加一个 State 计算表,但首选方法是创建一个虚拟表。此表仅在度量值计值时存在。
有一系列的 DAX 函数可用于创建虚拟表。使用这些函数的一般复杂性在于,它们的结果就是一个表。这意味着没有可用于查看结果的标准输出机制,这一点与度量值不同,我们可以创建一个 Power BI 视觉对象以查看 DAX 度量值的结果是否符合要求。在 Power BI 模型中使用相同的函数创建计算表可能会有所帮助,但无论如何,使用 DAX 表函数需要一定程度的抽象思维。
让我们回到“计算每个州的平均销售额”这个话题,函数 VALUES 将列引用作为其参数,并返回一个具有该列中唯一值的表。代码如下。
VALUES(Cities[State])
这个表表达式返回具有唯一 State 值的表。起到相同作用的函数是 DISTINCT,它也从列中返回唯一值;不同之处在于 DISTINCT 不包含空白值,这些空白值来自于不完整关系导致的空白行(请参见 第 2 章 模型设计中的图 2.5)。是否在结果中显示该空白值应该由您根据实际情况来决定。
每个州的销售额计算如下。
SalesPerState =
AVERAGEX(
VALUES(Cities[State]),
[Sales]
)
有一系列的 DAX 函数会返回表,但是我们不会在此处全都罗列。我们只将几个最常用的函数展开来说明。
• SUMMARIZE:尽管这是一个多种用途且复杂的函数,能够生成完整的类似数据透视表的结果,但是在 DAX 度量值中它可不是这样使用。此函数可以对 VALUES 函数做一个很好的补充:VALUES 返回一列中的唯一值,而 SUMMARIZE 可以返回多个列中值的唯一组合。例如,fSales 表中 CityID 和 ProductID 值的唯一组合可以通过如下代码获取(请注意,您必须在第一个参数中提供这个表本身)。
SUMMARIZE(fSales, fSales[CityID], fSales[ProductID])
• FILTER:此函数有两个参数,第一个是表(模型中的现有表或另一个表函数的结果),第二个参数是对表中每一行计算的表达式。表达式应产生 true 或 false,并且 FILTER 在结果中仅包含计算结果为 true 的行。例如,下面的表达式返回德国的城市。
FILTER(Cities, Cities[Country] = "Germany")
• TOPN:与 FILTER 一样,TOPN 返回表中行的子集。根据某些条件,将返回表中最上面或最下面的几行。您可以提供所需的行数、从中获取行的表、对每行进行排名的值,以及是希望将它们从高到低或从低到高排序。例如,要创建一个销售额排名前 15 的客户的表,代码如下。
TOPN(15, Customers, [Sales], DESC)
• CROSSJOIN:以下介绍的这些函数通过两个输入表创建单个表。 CROSSJOIN 返回两个输入表中每一行的交叉组合的表。下面的示例返回一个包含产品和城市的所有组合的表,其中包含 Cities 表和 Products 表中的所有列。
CROSSJOIN(Cities, Products)
• GENERATE::与 CROSSJOIN 一样,此函数也会返回一个输入表组合后生成的表。函数的第二个参数是一个表表达式,该表达式针对第一个参数中的表中的每一行进行计算。如果此表达式恰好为特定行返回空表,则该行不会包含在结果中。或者,您可以使用 GENERATEALL,它包含这样的行,但在表表达式的列中包含空白值。例如,下面的表达式返回一个包含城市和产品的表,同样包含 Cities 表和 Products 表中的所有列,其中产品只考虑在该城市有销售额的情况。
GENERATE(Cities, FILTER(Products, [Sales] > 0))
您将在第二部分中遇到一些其他的表函数,我们将在需要用到它们时详细介绍。
4.6.3 表函数中的上下文
上面的 GENERATE 示例可能直观上很清楚,但如果你深入思考,它实际上是一个相当复杂的例子。若要清楚知晓此类表达式到底做了什么,理解 DAX 上下文在表函数中的工作方式非常重要。让我们在一个完整的度量值公式中使用 GENERATE 来说明这一点,代码如下。
AvgUnitAmount1 =
AVERAGEX(
GENERATE(
Cities,
FILTER(
Products,
[Sales] > 10000
)
),
AVERAGE(fSales[UnitAmount])
)
此度量值的目的是计算城市中所有产品销售交易的每笔销售交易的平均产品数量(单位Amount)。这些产品的销量超过10000。你能发现这个公式中的错误吗?
在 Power BI 视觉对象中使用此度量值时,将在查询上下文中对其进行计算。这个上下文可以是任何东西;它可能包含 Power BI 模型中列上的一个或多个筛选器。
AVERAGEX 函数有两个参数,这两个参数各自在不同的上下文中进行计算:
• 第一个参数是表表达式,与 AVERAGEX 函数本身的上下文一致。
• 第二个参数是标量表达式,在第一个参数的表中每一行的行上下文中计算。
您可能已经从前面讨论的 Sales2 度量值中注意到了,该度量值在 SUMX 的第二个参数中使用了直接的列引用。此处的行上下文提供了直接使用表中的列进行计算的可能性。实际上,行上下文转换发生在查询上下文之前,而在计算列中的行上下文中,根本没有筛选器;在这种情况下,查询上下文中的筛选器仍然存在。
|  | 使用虚拟表时出现的常见错误与表聚合函数中的行上下文有关。下面是一个简单的示例。 ThisDoesntWork = SUMX( VALUES(fSales[UnitAmount]), fSales[Tax] ) 虽然此公式使用了 fSales 表中的两列,但却无法直接引用 Tax 列,因为行上下文不在 fSales 表中,而是在VALUES 函数的结果中。此结果是一个只有一列的表,即fSales[UnitAmount],也只有该列可以直接被使用。 |
| ———————————————————— | ———————————————————— |
| 使用虚拟表时出现的常见错误与表聚合函数中的行上下文有关。下面是一个简单的示例。 ThisDoesntWork = SUMX( VALUES(fSales[UnitAmount]), fSales[Tax] ) 虽然此公式使用了 fSales 表中的两列,但却无法直接引用 Tax 列,因为行上下文不在 fSales 表中,而是在VALUES 函数的结果中。此结果是一个只有一列的表,即fSales[UnitAmount],也只有该列可以直接被使用。 |
| ———————————————————— | ———————————————————— |
上面讨论的表函数 FILTER、TOPN 和 GENERATE 的工作方式相同:在调用函数的上下文中计算表参数;另一个参数在行上下文中计值。在以上 GENERATE 这个示例时,这意味着我们在行上下文中计算了一个表表达式。
对于上面的 AvgUnitAmount1 的公式,我们有一系列上下文在起作用。让我们一步一步地分解它们。
-
AVERAGEX:在查询上下文中计算。
-
GENERATE:在与 AVERAGEX 相同的上下文中进行计算。
-
Cities:仍在相同的上下文中进行计算。
-
FILTER:在 Cities 表的行上下文中进行计算。
-
Products:在与 FILTER 相同的上下文中进行计算。
-
[Sales]:由于这是对另一个度量值的调用,因此隐式的 CALCULATE 函数创建了一个筛选上下文。对于每一个调用,都确定了 Cities 表中的一行及在 Products 表中的一行。在筛选上下文中,将添加 Cities 表和 Products 表中每列的筛选器。因此,结果是该产品在该城市的销售情况。
-
AVERAGE:GENERATE 函数返回一个城市和产品组合的表,AVERAGE 在这个表的行上下文中进行计算。
那么这个公式中的错误在哪里呢?
在最后一步:尽管此步骤是针对城市和产品的正确组合进行计算的,但它是在行上下文中计算的。这意味着只有查询上下文中已存在的筛选器才会对 AVERAGE 计算产生影响。当前城市和产品不会影响计算,因为 Cities 表和 Products 表上没有(其他)筛选器来选择当前城市和产品。解决此问题的方法是将行上下文转换为筛选上下文,就像在步骤 6 中所做的那样。我们可以通过添加 CALCULATE 来执行此操作:
AvgUnitAmount2 =
AVERAGEX(
GENERATE(
Cities,
FILTER(
Products,
[Sales] > 10000
)
),
CALCULATE(AVERAGE(fSales[UnitAmount]))
)
|  | 在大多数情况下,最好将平均单位金额计算放在单独的度量中,因为其他地方可能需要用到它。您只需编写一次计算逻辑,此后,对该度量值的调用将自动对行上下文进行转换。 |
| ———————————————————— | ———————————————————— |
| 在大多数情况下,最好将平均单位金额计算放在单独的度量中,因为其他地方可能需要用到它。您只需编写一次计算逻辑,此后,对该度量值的调用将自动对行上下文进行转换。 |
| ———————————————————— | ———————————————————— |
在 DAX 中设计更复杂的度量值时,仔细跟踪上下文和上下文转换至关重要。
以上所述的这个公式中还有另一个数学计算错误:我们计算平均单位金额的城市/产品组合的平均值。这不一定等于这些城市/产品组合的所有销售交易的平均单位金额。为了解决这个问题,我们需要使用另外一种不同的方法,后文会详细展开说明,让我们先关注另外一个重要的问题:性能。
4.6.4 使用表函数的性能注意事项
我们使用 Power BI 的最终目标始终是尽快提供结果,任何时候我们都应该考虑性能问题。因此,在 DAX 中使用虚拟表时,需要时刻注意以下几点。
首先,要认识到虚拟表是由 DAX 引擎在内存中构造的,这一点很重要。这意味着虚拟表越大,需要的内存就越多,性能降低的风险就越高。您甚至可能遇到“没有足够的内存来执行此计算”的错误。因此,你应该问问自己,你使用的表是否可以变小:具体来说,你是否真的需要表中所有的列?
在上面的 AvgUnitAmount2 度量中,情况显然并非如此。GENERATE 创建的虚拟表包含Cities 表和 Products 表中的所有列。但对于计算结果而言,实际上只需要表中的唯一键就够了:这些唯一键确定 fSales 中的哪些行被筛选,从而确定 Sales 度量值的计算结果。我们对此进行优化,代码如下。
AvgUnitAmount3 =
AVERAGEX(
GENERATE(
VALUES(Cities[CityID]),
FILTER(
VALUES(Products[ProductID]),
[Sales] > 10000
)
),
CALCULATE(AVERAGE(fSales[UnitAmount]))
)
我们需要考虑的第二件事是虚拟表中的行数。显然这也是决定表的大小的一个因素,更重要的是,它也同时决定了表聚合中的迭代次数。
例如,如果产品的购买价格存储在 Products 表中,则可以根据 fSales 表计算总采购金额,代码如下。
TotalPurchased1 =
SUMX(
fSales,
fSales[UnitAmount] * RELATED(Products[PurchasePrice])
)
相反,您可以通过让 SUMX 迭代 Products 表而不是 fSales 表来优化迭代次数。或者更好的是,迭代 PurchasePrice 列的唯一值,代码如下。
TotalPurchased2 =
SUMX(
VALUES(Products[PurchasePrice]),
Products[PurchasePrice] *CALCULATE(SUM(fSales[UnitAmount]))
)
在此变式中,与购买价格值相对应的所有交易记录将被聚合。请注意此处的CALCULATE,将行上下文转换为筛选上下文并筛选正确的销售交易记录。
| | 内存使用情况和迭代次数是 CROSSJOIN 函数在 DAX 度量值中通常不是一个有吸引力的函数的原因之一。CROSSJOIN 返回的行数可能很大,这很容易导致内存问题。在表聚合中包含 CROSSJOIN 时,如下所示(A 和 B 是两个任意表表达式): SUMX( CROSSJOIN(A, B), [Sales] ) 一个更加便捷的方法是根本不使用CROSSJOIN,代码如下。 SUMX( A, SUMX( B, [Sales] ) ) |
| ———————————————————— | ———————————————————— |
更有效的方法是根本不对虚拟表进行迭代,而是将其用于筛选。这正是下一节的主题。
4.6.5 使用表函数进行筛选
长久以来,我们在使用 DAX 时常常感叹于表和筛选之间的深层联系。在本节中,您将了解这个联系是什么,以及如何利用它。
1.使用 CALCULATETABLE
正如我们在本章前面讨论的那样,表聚合函数(如 SUMX)中使用的表表达式的上下文,与表聚合函数本身的上下文是一致的。然而你可能并不总是想要这样的结果:有时,你需要一个不同的上下文。DAX 为此专门提供了一个函数:CALCULATETABLE。
跟它的表兄弟 CALCULATE 一样,CALCULATETABLE 在计算表达式之前会更改上下文。在 CALCULATE 中,此表达式必须返回标量值;在 CALCULATETABLE 中,它必须是表表达式。除了这一点不同之外,该函数也是按照与 CALCULATE 相同的四步过程工作。
-
设置筛选上下文。
-
从筛选器参数引用的列或表中删除现有筛选器。
-
添加在筛选器参数中指定的新筛选器。
-
计算第一个参数中的表表达式。
通常,CALCULATE 和 CALCULATETABLE 可以互换使用,以下面的公式为例。
AveragePerCity_Canada1 =
AVERAGEX(
CALCULATETABLE(
VALUES(Cities[CityID]),
Cities[Country] = "Canada"
),
[Sales]
)
您可以将此度量值重写为简单的计算公式,代码如下。
AveragePerCity_Canada2 =
CALCULATE(
AVERAGEX(
VALUES(Cities[CityID]),
[Sales]
),
Cities[Country] = "Canada"
)
这两种计算都返回加拿大(Canada)的每个城市的平均销售额(当然,这取决于查询上下文)。但请注意:两者之间存在着技术差异。在第一个公式中,Cities[Country] = “Canada” 筛选器应用于 Cities 表的计算,而在第二个公式中,筛选器应用于 Cities 表和 Sales 度量值的计算。虽然在这种情况下,此差异不会影响度量值的结果,但有些时候您可能会用到一些受到此差异影响的更高级的度量值。
|  | 与 CALCULATE 一样,CALCULATETABLE 创建了筛选上下文。在计算列中使用时,将在每行中添加新的筛选器以选择该行。在新上下文中计算相关表时,关系会传递筛选器,并且相关表将被筛选为仅链接到当前表的行。这就是为什么用于检索另一个表的相关部分的 RELATEDTABLE 函数只不过是没有筛选器参数的CALCULATETABLE 函数的原因。 |
| ———————————————————— | ———————————————————— |
| 与 CALCULATE 一样,CALCULATETABLE 创建了筛选上下文。在计算列中使用时,将在每行中添加新的筛选器以选择该行。在新上下文中计算相关表时,关系会传递筛选器,并且相关表将被筛选为仅链接到当前表的行。这就是为什么用于检索另一个表的相关部分的 RELATEDTABLE 函数只不过是没有筛选器参数的CALCULATETABLE 函数的原因。 |
| ———————————————————— | ———————————————————— |
使用 CALCULATETABLE,可以将筛选器添加到表评估中。有趣的是,您同样可以使用表来添加筛选器。
2.筛选器和表
既然我们已经介绍了表函数,是时候回过头来重新审视筛选器了。之前,我们在查询上下文和筛选上下文中引入了筛选器,作为 Power BI 模型中的列上的“规则”,如“Cities 表 [Country] 列必须等于 France 或 Germany”。您可以将此规则视为 Country 列应包含的值;或者,从另一个角度来看,将其视为具有两行的单列表,其中包含 France 和 Germany。
实际上,这正是筛选器的工作方式以及 CALCULATE 函数的工作模式:通过添加一些定义列中哪些值被选中的表,可能会替换实现筛选的现有表。一个基本的定律如下。
每一个筛选器都是一张表,任何一张表都可以被当作筛选器。
此定律意味着 CALCULATE 中的任何简单筛选器参数都可以重写为一个表。例如,请查看以下公式。
SalesFranceGermany =
CALCULATE(
[Sales],
Cities[Country] IN {"France", "Germany"}
)
此处的筛选器参数等效于下面的表表达式。
FILTER(
ALL(Cities[Country]),
Cities[Country] IN {"France", "Germany"}
)
因此,此筛选器的含义从字面上看是:在所有 Country 的值中,仅选择了 France和 Germany 这两个国家。
|  | 这就解释了为什么像下面这样的公式有效: CALCULATE( [Sales], Cities[Country] = “France” || Cities[Country] = “Germany” ) 虽然这不是最简单的筛选器参数,但它等效于: FILTER( ALL(Cities[Country]), Cities[Country] = “France” || Cities[Country] = “Germany” ) |
| ———————————————————— | ———————————————————— |
| 这就解释了为什么像下面这样的公式有效: CALCULATE( [Sales], Cities[Country] = “France” || Cities[Country] = “Germany” ) 虽然这不是最简单的筛选器参数,但它等效于: FILTER( ALL(Cities[Country]), Cities[Country] = “France” || Cities[Country] = “Germany” ) |
| ———————————————————— | ———————————————————— |
大多数作为筛选器引入的 DAX 函数实际上是表函数,正如您已经从上面的 FILTER 表达式中看到的那样,该表达式使用 ALL 作为表函数。实际上,ALL 函数系列都是表函数:ALL(Cities[Country])是一个包含所有唯一国家/地区的单列表,ALL(Cities[Country], Cities[State])是一个两列表,其中包含在 Cities 表中找到的所有唯一的国家/地区和州/省组合。
| | 并非所有筛选器参数中使用的函数都是表函数:USERELATIONSHIP 和 CROSSFILTER 会更改关系行为,并且不会创建表。KEEPFILTERS 更改了 CALCULATE 的行为,但不能用于创建表。REMOVEFILTERS 的功能类似于筛选器参数中的 ALL,不能用于创建表。 |
| ———————————————————— | ———————————————————— |
甚至当我们排除了像 TOTALYTD 这样的快捷方式版本时,时间智能函数也是表函数。每个表都创建一个单列表,其中包含指定时间段内的日期。这意味着您可以在表聚合函数中使用这些函数,例如,计算年初至今每天的平均销售额可以用如下的度量值。
AverageSalesPerDay_YTD =
AVERAGEX(
DATESYTD('Date'[Date]),
[Sales]
)
筛选器即是表 这一定律的更令人兴奋的用途是,您可以使用任何表(包括虚拟表)作为 CALCULATE 函数中的筛选器。举个简单的例子,假设您希望有一个度量值来返回所选城市所在的一个或多个国家的总销售额。如果您确定在此计算的查询上下文中,Country 列被筛选,则下面的公式并不难理解。
SalesWholeCountry1 =
CALCULATE(
[Sales],
ALLEXCEPT(Cities, Cities[Country])
)
此计算将从 Cities 表中去掉除 Country 列之外的所有列上的筛选器。因此,如果查询上下文包含筛选器“在 City 列上选择了亚特兰大”和“在 Country 列上选择了美国”,则生成的筛选上下文只剩下“在 Country 列上选择了美国”这一个筛选器。
但是,如果查询上下文一开始就只有“在 City 列上选择了亚特兰大”这一个筛选器,那么我们就会遇到麻烦:删除此筛选器意味着去掉了所有的筛选,返回了所有的数据!为了解决这个问题,我们需要重新输入一个“在 Country 列上选择了美国”的筛选放到上下文中,并且它应该派生自 City 列上的筛选器。这可以通过表筛选来完成,代码如下。
SalesWholeCountry2 =
CALCULATE(
[Sales],
ALL(Cities),
VALUES(Cities[Country])
)
想要看明白此处到底发生了什么,需要深刻地理解这一点:筛选器参数计算所需的上下文与 CALCULATE 本身上下文完全一致。在仅选择一个城市的查询上下文中,VALUES(Cities[Country]) 表达式返回一个单列表,其中包含该城市所在的国家。这正是我们实现想要的计算所需的筛选器。
再举个例子,下面的公式计算销售额前 10000 名的客户的总销售额。
SalesLargestCustomers1 =
CALCULATE(
[Sales],
TOPN(10000, ALL(Customers), [Sales], DESC)
)
请注意,我们在这里使用 ALL(Customers) 来排除可能会在查询上下文中存在着一些筛选器,这些筛选器返回的是客户的子集。TOPN 函数返回销售额前 10000 名的客户(作为 Customers 表的子集,包括了所有列,当然您可能希望在此处删除不需要的列)。然后,此表将用作筛选器。
此公式清楚地表明了为什么使用表筛选比使用表聚合更可取。如下所示的代码是此度量值的表聚合替代方法。
SalesLargestCustomers2 =
SUMX(
TOPN(10000, ALL(Customers), [Sales], DESC),
[Sales]
)
请认真想一下这个问题:在进行这两个计算时分别调用了多少次 Sales 度量值?当然,这取决于我们的 Customers 表中的客户数量。假设我们有 60000 个客户。TOPN 函数必须为每个客户都调用一次 Sales 度量值,以确定哪些是销售额最大的客户。完成此操作后,SalesLargestCustomers1 度量值只需要对 Sales 进行一次额外的调用:TOPN 表将作为筛选器,从而为销售额最大的客户创建上下文。但是,SalesLargestCustomers2 度量值将遍历 TOPN 表并为每行再次调用 Sales。换句话说,此度量值总共调用了 Sales度量值 70000 次,而 SalesLargestCustomers1 度量值仅调用 60001 次!即便 DAX 引擎可能会优化此处的计算过程,但其中的差异依旧会很大。
与查询上下文中的筛选器不同的是,表筛选器可以具有多个列,当您意识到这一点时,将表用作筛选器将变得更加强大。这意味着,本章前面部分中我们讨论过的仍然存在问题的 AvgUnitAmount3 度量值,现在有了一个解决方案,代码如下。
AvgUnitAmount4 =
CALCULATE(
AVERAGE(fSales[UnitAmount]),
GENERATE(
VALUES(Cities[CityID]),
FILTER(
VALUES(Products[ProductID]),
[Sales] > 10000
)
)
)
这次,我们使用 GENERATE 来提供一个筛选器,用于选择销售额超过 10000 的城市和产品的组合,而不是 GENERATE 表达式上表聚合的平均值。然后,我们计算与所选城市/产品组合相对应的所有销售交易的平均单位金额。现在,我们不仅有了正确的计算平均的方法,而且还消除了对 GENERATE 表的迭代,这将有助于进一步提高此度量值的性能。
4.6.6 使用 TREATAS
使用表筛选器时有一个重要的约束:这些表必须真正地筛选执行计算的表。如果添加一个与模型其余部分没有任何关系的表筛选器不会执行任何操作。
例如,以下公式并不会返回英国的销售额。
UKSales_wrong =
CALCULATE(
[Sales],
ROW("Country", "United Kingdom")
)
为什么这不起作用呢?原因是 Power BI 模型无法确定使用 ROW 函数创建的这个随性的表中,到底哪一列的名字是 Country,它应筛选 Cities 表,该表同样也包含 Country 列)。你可能会说,“哎呀,字段名称是相同的,所以 DAX 引擎应该可以假设这就是公式的本意吧”;如果真的是这样,一些模型在许多不同的表中可能具有相同的列名,这可能会导致一些完全不可预知的结果。
为了能够被用作筛选器,DAX 引擎应该能够识别虚拟表是否连接到模型中的表或某些列。这种连接称为数据沿袭(Lineage),简而言之,这意味着在创建虚拟表时,DAX 会跟踪虚拟表中列的来源的原始列。让我们再看一次 GENERATE 这个表达式。
GENERATE(
VALUES(Cities[CityID]),
FILTER(
VALUES(Products[ProductID]),
[Sales] > 10000
)
)
很明显,Cities[CityID] 是模型中的一列,并且由于 VALUES 从该列中获取唯一值,因此 VALUES(Cities[CityID])具有该列的数据沿袭。同样的道理,VALUES(Products[ProductID])与 Products 表中的 ProductID 列具有数据沿袭。GENERATE 函数创建了一个表,其中包含两个 VALUES 表达式中的值组合,因此生成的表中的每一列都具有与相应的模型列一致的数据沿袭。
大多数表函数会保留它们来源的列的数据沿袭。但是,某些函数允许以奇怪的方式形成新的表,这在数据沿袭方面可能存在问题。例如,UNION 函数允许从两个源表中获取行来组合成为一个新的表,这两个表可能具有冲突的数据沿袭。如果是这样,则结果表中的列与模型中的任何现有的列都没有数据沿袭。
在某些情况下,您也可能希望虚拟表的数据沿袭与默认值不同。DAX 通过 TREATAS 函数提供了一个解决方案,该函数强制模型中某个表的列具有特定的数据沿袭。
TREATAS 是专门用在 CALCULATE 或 CALCULATETABLE 函数中作为筛选器参数的另一个例子。下面的公式正确计算了英国的销售额(尽管有更简单的方法可以做到这一点)。
UKSales_correct =
CALCULATE(
[Sales],
TREATAS(
ROW("Country", "United Kingdom"),
Cities[Country]
)
)
请注意,TREATAS 不要求列的名称相同。我们可以在 ROW 表达式中将列命名为我们想要的任何名称。TREATAS 也适用于多列的表,在这种情况下,应为创建的表中的每一列指定一个模型中的列。您可以在第 9 章 公司间业务 中找到使用 TREATAS 的综合示例。
4.6.7 DAX 变量
DAX 表函数和筛选大大提高了使用 DAX 可以完成的计算的复杂性。然而有利就有弊,公式可能会因此变得很长。更重要的是,在整个度量值的书写过程中,不同位置的上下文可能完全不同,在得到正确结果的道路上往往会出现各种问题。
DAX 变量,使得这类设计高级 DAX 代码的工作变得轻松了不少。该名称有些奇怪,因为 DAX 变量的用途是,您可以计算一次某些内容,稍后在其他情况下(通常是其他上下文)使用它,而不必担心变量的计算。换句话说,DAX 变量被用作常量!
变量是使用 VAR 关键字声明的。可以声明多个变量,并且一个变量的声明可以使用之前声明的另一个变量的值。变量的声明由 RETURN 关键字来关闭。
VAR ThisValue = 5
RETURN
...
知道 DAX 变量可用于 DAX 公式中的任何表达式是有必要的。变量可以包含标量值,但也可以是表。下面的(看上去相当荒谬的)公式是一段正确的 DAX 代码。
VariableTest =
VAR Variable1 = 3
VAR Variable2 = Variable1 + 5
RETURN
CALCULATE(
VAR Variable3 = MAX(fSales[UnitAmount])
RETURN
SUM(fSales[Tax]) + Variable2 + Variable3,
VAR Variable4 = 4
VAR TableVariable =
FILTER(
ALL(fSales[UnitAmount]),
fSales[UnitAmount] = Variable4
)
RETURN
TableVariable
)
变量声明在公式中的位置决定了计算变量的上下文。例如,上面的 Variable3 变量是在通过将 TableVariable 表筛选器应用于此度量值的原始查询上下文而形成的筛选上下文中计算的。如果 Variable3 是在 Variable2 之后声明的,那么它将在查询上下文中进行计算。注意 Variable4 和 TableVariable 在 CALCULATE 的筛选器参数中使用;两者都在原始查询上下文中进行计算。
每个变量都有自己的作用域,这意味着它不能在声明它的表达式之外使用。在上面的公式中,Variable3 不能用于定义 TableVariable;Variable3 是 CALCULATE 的第一个参数,在其他位置,它是无效的。相反,Variable4 和 TableVariable 不能在 CALCULATE 的第一个参数中使用。Variable1 和 Variable2 是整个表达式的一部分,可以在任何地方使用。
DAX 变量不仅可以帮助简化计算流程,还可以使公式更具可读性,只需使用清晰的变量名称即可。让我们再次回顾一下 AvgUnitAmount4 的度量。
AvgUnitAmount4 =
CALCULATE(
AVERAGE(fSales[UnitAmount]),
GENERATE(
VALUES(Cities[CityID]),
FILTER(
VALUES(Products[ProductID]),
[Sales] > 10000
)
)
)
如果使用变量,可以将此公式进行简化,代码如下。
AvgUnitAmount5 =
VAR LargeCityProductCombinations =
GENERATE(
VALUES(Cities[CityID]),
FILTER(
VALUES(Products[ProductID]),
[Sales] > 10000
)
)
RETURN
CALCULATE(
AVERAGE(fSales[UnitAmount]),
LargeCityProductCombinations
)
永远记住,DAX 变量是常量!下面的变体不会得到正确的结果。
AvgUnitAmount_wrong =
VAR LargeProducts =
FILTER(
VALUES(Products[ProductID]),
[Sales] > 10000
)
VAR LargeCityProductCombinations =
GENERATE(
VALUES(Cities[CityID]),
LargeProducts
)
RETURN
CALCULATE(
AVERAGE(fSales[UnitAmount]),
LargeCityProductCombinations
)
通过将 FILTER 表达式放在变量中,我们将其转换为常量表。然而,在 GENERATE 函数中,我们却希望为每个城市重新确定产品列表,因此结果必然是错误的。
总结
在本章中,您已经了解了行上下文、查询上下文和筛选上下文,以及上下文在评估 DAX 公式时所起到的作用。我们已经讨论了如何使用 CALCULATE 函数通过删除筛选器并将筛选器添加到现有上下文中来转换上下文。此外,我们还研究了时间智能函数,这些函数提供了专门针对公历量身定制的筛选器。
接着,我们重点介绍了 DAX 表函数,这些函数使我们能够聚合表以及在 DAX 公式中使用自定义的虚拟表。使用虚拟表在使用“标准”的 DAX 函数和筛选之前提供了丰富的分析功能。我们讨论了表和筛选器之间的深层次联系,这允许我们将任何表用作筛选器。最后,我们讨论了 DAX 变量,通过使用这些变量可以更轻松地在 DAX 中实现复杂逻辑,并提高 DAX 代码的可读性。
所有这些都是使用 DAX 探索更高级分析所需的基本概念。在这关键的一章之后,本书的第二部分将专注于将以上讨论的所有概念应用于实际的商业案例。我们的期望是,通过浏览这些案例,您将进一步领略并理解 DAX 的强大功能,由此您将受到启发,并使用 DAX 计算来解决自己的业务问题。
第 5 章 基于 DAX 的安全性 专门介绍 Power BI 模型中的安全性。在这一章,您将看到,在设计安全性时,DAX、上下文和筛选方面的知识早就已经找到了许多用武之地。
注释:
1 译者注:此处应注意,并不是在所有情况下都 “只”筛选当前的行。在本例中所展示的数据,因为不存在完全相同的行,因此每一行上由行上下文转换而来的筛选上下文都不相同,这些筛选上下文起作用时只会将这个唯一行筛选出来。但是,如果表中的两行(甚至多行)内容完全相同,那么每一行上的由行上下文转换而来的筛选上下文也完全相同,并且都筛选了两行(或所有相同的行),结果很显然会是错误的。并且本例只是作者用来阐述上下文转换过程的一个简单示例,在实际的业务场景中并不会真正出现。因此,这种计算方法(仅对于使用SUM求和而言)并不建议使用。
2 译者注:此选项不能与一对一关系或多对一关系同时使用。OneWay_RightFiltersLeft同样也是如此。